Интерфейс запросов Active Record
Это руководство раскрывает различные способы получения данных из базы данных, используя Active Record.
После его прочтения, вы узнаете:
- Как искать записи, используя различные методы и условия.
- Как определять порядок, получаемые атрибуты, группировку и другие свойства поиска записей.
- Как использовать нетерпеливую загрузку (eager loading) для уменьшения числа запросов к базе данных, необходимых для получения данных.
- Как использовать методы динамического поиска.
- Как использовать цепочки методов (method chaining), для использования нескольких методов Active Record одновременно.
- Как проверять существование отдельных записей.
- Как выполнять различные вычисления в моделях Active Record.
- Как запускать EXPLAIN на relations.
1. Что такое интерфейс запросов Active Record?
Если вы использовали чистый SQL для поиска записей в базе данных, то скорее всего обнаружите, что в Rails есть лучшие способы выполнения тех же операций. Active Record ограждает вас от необходимости использования SQL во многих случаях.
Active Record выполнит запросы в базу данных за вас, он совместим с большинством СУБД, включая MySQL, MariaDB, PostgreSQL и SQLite. Независимо от того, какая используется СУБД, формат методов Active Record будет всегда одинаковый.
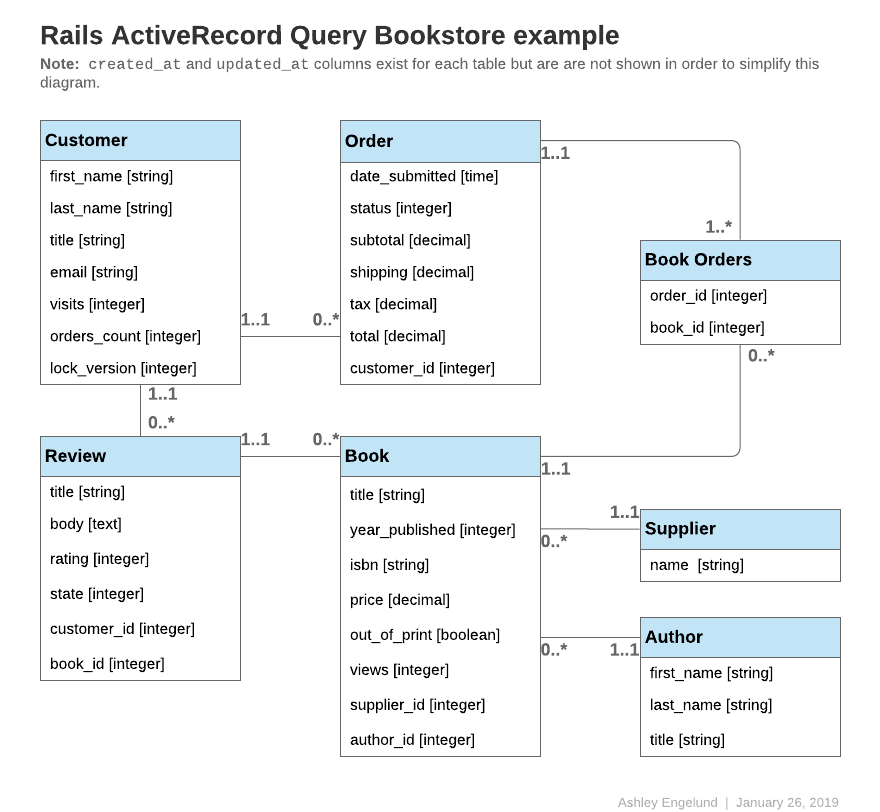
Примеры кода далее в этом руководстве будут относиться к некоторым из этих моделей:
Все модели используют id как первичный ключ, если не указано иное.
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
class Book < ApplicationRecord
belongs_to :supplier
belongs_to :author
has_many :reviews
has_and_belongs_to_many :orders, join_table: 'books_orders'
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
scope :out_of_print_and_expensive, -> { out_of_print.where('price > 500') }
scope :costs_more_than, ->(amount) { where('price > ?', amount) }
end
class Customer < ApplicationRecord
has_many :orders
has_many :reviews
end
class Order < ApplicationRecord
belongs_to :customer
has_and_belongs_to_many :books, join_table: 'books_orders'
enum :status, [:shipped, :being_packed, :complete, :cancelled]
scope :created_before, ->(time) { where(created_at: ...time) }
end
class Review < ApplicationRecord
belongs_to :customer
belongs_to :book
enum :state, [:not_reviewed, :published, :hidden]
end
class Supplier < ApplicationRecord
has_many :books
has_many :authors, through: :books
end
2. Получение объектов из базы данных
Для получения объектов из базы данных Active Record предоставляет несколько методов поиска. В каждый метод поиска можно передавать аргументы для выполнения определенных запросов в базу данных без необходимости писать на чистом SQL.
Методы следующие:
annotatefindcreate_withdistincteager_loadextendingextract_associatedfromgrouphavingincludesjoinsleft_outer_joinslimitlocknoneoffsetoptimizer_hintsorderpreloadreadonlyreferencesreorderreselectregroupreverse_orderselectwhere
Методы поиска, возвращающие коллекцию, такие как where и group, возвращают экземпляр ActiveRecord::Relation. Методы, ищущие отдельную сущность, такие как find и first, возвращают отдельный экземпляр модели.
Вкратце основные операции Model.find(options) таковы:
- Преобразовать предоставленные опции в эквивалентный запрос SQL.
- Выполнить запрос SQL и получить соответствующие результаты из базы данных.
- Создать экземпляр эквивалентного объекта Ruby подходящей модели для каждой строки результата запроса.
- Запустить колбэки
after_findи далееafter_initialize, если таковые имеются.
2.1. Получение одиночного объекта
Active Record предоставляет несколько различных способов получения одиночного объекта.
2.1.1. find
Используя метод find, можно получить объект, соответствующий определенному первичному ключу (primary key) и предоставленным опциям. Например:
# Найдем покупателя с первичным ключом (id) 10.
irb> customer = Customer.find(10)
=> #<Customer id: 10, first_name: "Ryan">
SQL эквивалент этого такой:
SELECT * FROM customers WHERE (customers.id = 10) LIMIT 1
Метод find вызывает исключение ActiveRecord::RecordNotFound, если соответствующей записи не было найдено.
Этот метод также можно использовать для получения нескольких объектов. Вызовите метод find и передайте в него массив первичных ключей. Возвращенным результатом будет массив, содержащий все записи, соответствующие представленным первичным ключам. Например:
# Найдем покупателей с первичными ключами 1 и 10.
irb> customers = Customer.find([1, 10]) # OR Customer.find(1, 10)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 10, first_name: "Ryan">]
SQL эквивалент этого такой:
SELECT * FROM customers WHERE (customers.id IN (1,10))
2.1.2. take
Метод take извлекает запись без какого-либо явного упорядочивания. Например:
irb> customer = Customer.take
=> #<Customer id: 1, first_name: "Lifo">
SQL эквивалент этого такой:
SELECT * FROM customers LIMIT 1
Метод take возвращает nil, если ни одной записи не найдено, и исключение не будет вызвано.
В метод take можно передать числовой аргумент, чтобы вернуть это количество результатов. Например
irb> customers = Customer.take(2)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 220, first_name: "Sara">]
SQL эквивалент этого такой:
SELECT * FROM customers LIMIT 2
Метод take! ведет себя подобно take, за исключением того, что он вызовет ActiveRecord::RecordNotFound, если не найдено ни одной соответствующей записи.
Получаемая запись может отличаться в зависимости от подсистемы хранения СУБД.
2.1.3. first
Метод first находит первую запись, упорядоченную по первичному ключу (по умолчанию). Например:
irb> customer = Customer.first
=> #<Customer id: 1, first_name: "Lifo">
SQL эквивалент этого такой:
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 1
Метод first возвращает nil, если не найдено соответствующей записи, и исключение не вызывается.
Если скоуп по умолчанию содержит метод order, first возвратит первую запись в соответствии с этим упорядочиванием.
В метод first можно передать числовой аргумент, чтобы вернуть это количество результатов. Например
irb> customers = Customer.first(3)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 2, first_name: "Fifo">, #<Customer id: 3, first_name: "Filo">]
SQL эквивалент этого такой:
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 3
На коллекции, упорядоченной с помощью order, first вернет первую запись, упорядоченную по указанному в order атрибуту.
irb> customer = Customer.order(:first_name).first
=> #<Customer id: 2, first_name: "Fifo">
SQL эквивалент этого такой:
SELECT * FROM customers ORDER BY customers.first_name ASC LIMIT 1
Метод first! ведет себя подобно first, за исключением того, что он вызовет ActiveRecord::RecordNotFound, если не найдено ни одной соответствующей записи.
2.1.4. last
Метод last находит последнюю запись, упорядоченную по первичному ключу (по умолчанию). Например:
irb> customer = Customer.last
=> #<Customer id: 221, first_name: "Russel">
SQL эквивалент этого такой:
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 1
Метод last возвращает nil, если не найдено соответствующей записи, и исключение не вызывается.
Если скоуп по умолчанию содержит метод order, last возвратит последнюю запись в соответствии с этим упорядочиванием.
В метод last можно передать числовой аргумент, чтобы вернуть это количество результатов. Например
irb> customers = Customer.last(3)
=> [#<Customer id: 219, first_name: "James">, #<Customer id: 220, first_name: "Sara">, #<Customer id: 221, first_name: "Russel">]
SQL эквивалент этого такой:
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 3
На коллекции, упорядоченной с помощью order, last вернет последнюю запись, упорядоченную по указанному в order атрибуту.
irb> customer = Customer.order(:first_name).last
=> #<Customer id: 220, first_name: "Sara">
SQL эквивалент этого такой:
SELECT * FROM customers ORDER BY customers.first_name DESC LIMIT 1
Метод last! ведет себя подобно last, за исключением того, что он вызовет ActiveRecord::RecordNotFound, если не найдено ни одной соответствующей записи.
2.1.5. find_by
Метод find_by ищет первую запись, соответствующую некоторым условиям. Например:
irb> Customer.find_by first_name: 'Lifo'
=> #<Customer id: 1, first_name: "Lifo">
irb> Customer.find_by first_name: 'Jon'
=> nil
Это эквивалент записи:
Customer.where(first_name: 'Lifo').take
SQL эквивалент выражения выше, следующий:
SELECT * FROM customers WHERE (customers.first_name = 'Lifo') LIMIT 1
Отметьте, что в вышеприведенном SQL нет ORDER BY. Если вашим условиям find_by могут соответствовать несколько записей, следует применить упорядочивание, чтобы гарантировать детерминированный результат.
Метод find_by! ведет себя подобно find_by, за исключением того, что он вызовет ActiveRecord::RecordNotFound, если не найдено ни одной соответствующей записи. Например:
irb> Customer.find_by! first_name: 'does not exist'
ActiveRecord::RecordNotFound
Это эквивалент записи:
Customer.where(first_name: 'does not exist').take!
2.2. Получение нескольких объектов пакетами
Часто необходимо перебрать огромный набор записей, например, когда рассылаем письма всем покупателям или импортируем некоторые данные.
Это может показаться простым:
# Это может потребить слишком много памяти, если таблица большая.
Customer.all.each do |customer|
NewsMailer.weekly(customer).deliver_now
end
Но этот подход становится очень непрактичным с увеличением размера таблицы, поскольку Customer.all.each говорит Active Record извлечь таблицу полностью за один проход, создать объект модели для каждой строки и держать этот массив в памяти. В реальности, если имеется огромное количество записей, полная коллекция может превысить количество доступной памяти.
Rails предоставляет два метода, которые решают эту проблему путем разделения записей на дружелюбные к памяти пакеты для обработки. Первый метод, find_each, получает пакет записей и затем вкладывает каждую запись в блок отдельно как модель. Второй метод, find_in_batches, получает пакет записей и затем вкладывает весь пакет в блок как массив моделей.
Методы find_each и find_in_batches предназначены для пакетной обработки большого числа записей, которые не поместятся в памяти за раз. Если нужно просто перебрать тысячу записей, более предпочтителен вариант обычных методов поиска.
2.2.1. find_each
Метод find_each получает пакет записей и затем передает каждую запись в блок. В следующем примере find_each получает покупателей пакетами по 1000 записей, а затем передает их в блок один за другим:
Customer.find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
Этот процесс повторяется, извлекая больше пакетов при необходимости, пока не будут обработаны все записи.
find_each работает на классах модели, как показано выше, а также на relation:
Customer.where(weekly_subscriber: true).find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
только у них нет упорядочивания, так как методу необходимо собственное упорядочивание для работы.
Если у получателя есть упорядочивание, то поведение зависит от флажка config.active_record.error_on_ignored_order. Если true, вызывается ArgumentError, в противном случае упорядочивание игнорируется, что является поведением по умолчанию. Это можно переопределить с помощью опции :error_on_ignore, описанной ниже.
2.2.1.1. Опции для find_each
:batch_size
Опция :batch_size позволяет определить число записей, подлежащих получению в одном пакете, до передачи отдельной записи в блок. Например, для получения 5000 записей в пакете:
Customer.find_each(batch_size: 5000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:start
По умолчанию записи извлекаются в порядке увеличения первичного ключа. Опция :start позволяет вам настроить первый ID последовательности, когда наименьший ID не тот, что вам нужен. Это может быть полезно, например, если хотите возобновить прерванный процесс пакетирования, предоставив последний обработанный ID как контрольную точку.
Например, чтобы выслать письма только покупателям с первичным ключом, начинающимся от 2000:
Customer.find_each(start: 2000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:finish
Подобно опции :start, :finish позволяет указать последний ID последовательности, когда наибольший ID не тот, что вам нужен.
Это может быть полезно, например, если хотите запустить процесс пакетирования, используя подмножество записей на основании :start и :finish
Например, чтобы выслать письма только покупателям с первичным ключом от 2000 до 10000:
Customer.find_each(start: 2000, finish: 10000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
Другим примером является наличие нескольких воркеров, работающих с одной и той же очередью обработки. Можно было бы обрабатывать каждым воркером 10000 записей, установив подходящие опции :start и :finish в каждом воркере.
:error_on_ignore
Переопределяет настройку приложения, указывающую, должна ли быть вызвана ошибка, если в relation присутствует упорядочивание.
:order
Указывает порядок следования первичных ключей (может быть :asc или :desc). По умолчанию :asc.
Customer.find_each(order: :desc) do |customer|
NewsMailer.weekly(customer).deliver_now
end
2.2.2. find_in_batches
Метод find_in_batches похож на find_each тем, что они оба получают пакеты записей. Различие в том, что find_in_batches передает в блок пакеты как массив моделей, вместо отдельной модели. Следующий пример передаст в представленный блок массив из 1000 счетов за раз, а в последний блок содержащий всех оставшихся покупателей:
# Передает в add_customers массив из 1000 покупателей за раз.
Customer.find_in_batches do |customers|
export.add_customers(customers)
end
find_in_batches работает на классах модели, как показано выше, а также на relation:
# Передает в add_customers массив из 1000 недавно активных покупателей за раз.
Customer.recently_active.find_in_batches do |customers|
export.add_customers(customers)
end
только у них нет упорядочивания, так как методу необходимо собственное упорядочивание для работы.
2.2.2.1. Опции для find_in_batches
Метод find_in_batches принимает те же опции, что и find_each:
:batch_size
Как и для find_each, batch_size устанавливает, сколько записей будет извлечено в каждой группе. Например, получение пакетов по 2500 записей может быть определено как:
Customer.find_in_batches(batch_size: 2500) do |customers|
export.add_customers(customers)
end
:start
Опция :start позволяет вам указать начальный ID, начиная с которого будут выбраны записи. Как уже упоминалось, по умолчанию записи извлекаются по возрастанию первичного ключа. Например, чтобы получить покупателей начиная с ID: 5000 пакетами по 2500 записей, можно использовать следующий код:
Customer.find_in_batches(batch_size: 2500, start: 5000) do |customers|
export.add_customers(customers)
end
:finish
Опция finish позволяет указать последний ID записей для извлечения. Нижеследующий код показывает случай извлечения покупателей пакетами до покупателя с ID: 7000:
Customer.find_in_batches(finish: 7000) do |customers|
export.add_customers(customers)
end
:error_on_ignore
Опция error_on_ignore переопределяет настройку приложения, указывающую, должна ли быть вызвана ошибка, если в relation присутствует упорядочивание.
3. Условия
Метод where позволяет определить условия для ограничения возвращаемых записей, которые представляют WHERE-часть выражения SQL. Условия могут быть заданы как строка, массив или хэш.
3.1. Чисто строковые условия
Если вы хотите добавить условия в свой поиск, можете просто определить их там, подобно Book.where("title = 'Introduction to Algorithms'"). Это найдет все книги, где значение поля title равно 'Introduction to Algorithms'.
Создание условий в чистой строке подвергает вас риску SQL-инъекций. Например, Book.where("title LIKE '%#{params[:title]}%'") не безопасно. Смотрите следующий раздел для более предпочтительного способа обработки условий с использованием массива.
3.2. Условия с использованием массива
Что если заголовок может быть задан, скажем, как аргумент откуда-то извне? Поиск тогда принимает такую форму:
Book.where("title = ?", params[:title])
Active Record примет первый аргумент в качестве строки условия, а все остальные элементы подставит вместо знаков вопроса (?) в ней.
Если хотите определить несколько условий:
Book.where("title = ? AND out_of_print = ?", params[:title], false)
В этом примере первый знак вопроса будет заменен на значение в params[:title] и второй будет заменен SQL аналогом false, который зависит от адаптера.
Этот код значительно предпочтительнее:
Book.where("title = ?", params[:title])
чем такой код:
Book.where("title = #{params[:title]}")
по причине безопасности аргумента. Помещение переменной прямо в строку условий передает переменную в базу данных как есть. Это означает, что неэкранированная переменная, переданная пользователем, может иметь злой умысел. Если так сделать, вы подвергаете базу данных риску, так как если пользователь обнаружит, что он может использовать вашу базу данных, то он сможет сделать с ней что угодно. Никогда не помещайте аргументы прямо в строку условий!
Подробнее об опасности SQL-инъекций можно узнать из руководства Безопасность приложений на Rails.
3.2.1. Местозаполнители в условиях
Подобно тому, как (?) заменяют параметры, можно использовать ключи в условиях совместно с соответствующим хэшем ключей/значений:
Book.where("created_at >= :start_date AND created_at <= :end_date",
{ start_date: params[:start_date], end_date: params[:end_date] })
Читаемость улучшится, в случае если вы используете большое количество переменных в условиях.
3.2.2. Условия с использованием LIKE
Хотя аргументы условия автоматически экранируются, чтобы предотвратить инъекцию SQL, подстановки SQL LIKE (т.е. % и _) не экранируются. Это может вызвать неожидаемое поведение, если неочищенное значение используется в качестве аргумента. Например:
Book.where("title LIKE ?", params[:title] + "%")
В вышеприведенном коде намерением является соответствие заголовков, начинающихся с указанной пользователем строки. Однако, любое включение % или _ в params[:title] будет трактоваться как подстановки, что приведет к неожиданным результатам запроса. В некоторых обстоятельствах, это может также предотвратить использование базой данных предназначенного индекса, что приведет к гораздо медленному запросу.
Чтобы избежать этих проблемы, используйте sanitize_sql_like для экранирования символов подстановки в соответствующей части аргумента:
Book.where("title LIKE ?",
Book.sanitize_sql_like(params[:title]) + "%")
3.3. Условия с использованием хэша
Active Record также позволяет передавать условия в хэше, что улучшает читаемость синтаксиса условий. В этом случае передается хэш с ключами, соответствующими полям, которые хотите уточнить, и с значениями, которые вы хотите к ним применить:
Хэшем можно передать условия проверки только равенства, интервала и подмножества.
3.3.1. Условия равенства
Book.where(out_of_print: true)
Это сгенерирует такой SQL:
SELECT * FROM books WHERE (books.out_of_print = 1)
Имя поля также может быть строкой, а не символом:
Book.where('out_of_print' => true)
В случае отношений belongs_to, может быть использован ключ связи для указания модели, если как значение используется объект Active Record. Этот метод также работает с полиморфными отношениями.
author = Author.first
Book.where(author: author)
Author.joins(:books).where(books: { author: author })
3.3.2. Интервальные условия
Book.where(created_at: (Time.now.midnight - 1.day)..Time.now.midnight)
Это найдет все книги, созданные вчера, с использованием SQL выражения BETWEEN:
SELECT * FROM books WHERE (books.created_at BETWEEN '2008-12-21 00:00:00' AND '2008-12-22 00:00:00')
Это была демонстрация более короткого синтаксиса для примеров в Условия с использованием массива
Можно использовать интервалы без начала и без конца, чтобы создавать условия больше/меньше.
Book.where(created_at: (Time.now.midnight - 1.day)..)
Это сгенерирует подобный SQL:
SELECT * FROM books WHERE books.created_at >= '2008-12-21 00:00:00'
3.3.3. Условия подмножества
Если хотите найти записи, используя выражение IN, можете передать массив в хэш условий:
Customer.where(orders_count: [1, 3, 5])
Этот код сгенерирует подобный SQL:
SELECT * FROM customers WHERE (customers.orders_count IN (1,3,5))
3.4. Условия NOT
Запросы NOT в SQL могут быть созданы с помощью where.not:
Customer.where.not(orders_count: [1, 3, 5])
Другими словами, этот запрос может быть сгенерирован с помощью вызова where без аргументов и далее присоединенным not с переданными условиями для where. Это сгенерирует такой SQL:
SELECT * FROM customers WHERE (customers.orders_count NOT IN (1,3,5))
Если в запросе есть условие с использованием хэша с не-nil значениями на null столбце, записи со значениями nil на null столбце не будут возвращены. Например:
Customer.create!(nullable_country: nil)
Customer.where.not(nullable_country: "UK")
=> []
# Но
Customer.create!(nullable_country: "UK")
Customer.where.not(nullable_country: nil)
=> [#<Customer id: 2, nullable_country: "UK">]
3.5. Условия OR
Условия OR между двумя отношениями могут быть построены путем вызова or на первом отношении и передачи второго в качестве аргумента.
Customer.where(last_name: 'Smith').or(Customer.where(orders_count: [1, 3, 5]))
SELECT * FROM customers WHERE (customers.last_name = 'Smith' OR customers.orders_count IN (1,3,5))
3.6. Условия AND
Условия AND могут быть построены с помощью присоединения условий where.
Customer.where(last_name: 'Smith').where(orders_count: [1, 3, 5]))
SELECT * FROM customers WHERE customers.last_name = 'Smith' AND customers.orders_count IN (1,3,5)
Условия AND для логического пересечения между relation могут быть построены путем вызова and на первом relation и передачей второго в качестве аргумента.
Customer.where(id: [1, 2]).and(Customer.where(id: [2, 3]))
SELECT * FROM customers WHERE (customers.id IN (1, 2) AND customers.id IN (2, 3))
4. Упорядочивание
Чтобы получить записи из базы данных в определенном порядке, можете использовать метод order.
Например, если вы получаете ряд записей и хотите упорядочить их в порядке возрастания поля created_at в таблице:
Book.order(:created_at)
# ИЛИ
Book.order("created_at")
Также можете определить ASC или DESC:
Book.order(created_at: :desc)
# ИЛИ
Book.order(created_at: :asc)
# ИЛИ
Book.order("created_at DESC")
# ИЛИ
Book.order("created_at ASC")
Или сортировку по нескольким полям:
Book.order(title: :asc, created_at: :desc)
# ИЛИ
Book.order(:title, created_at: :desc)
# ИЛИ
Book.order("title ASC, created_at DESC")
# ИЛИ
Book.order("title ASC", "created_at DESC")
Если хотите вызвать order несколько раз, последующие сортировки будут добавлены к первой:
irb> Book.order("title ASC").order("created_at DESC")
SELECT * FROM books ORDER BY title ASC, created_at DESC
В большинстве СУБД при выборе полей с помощью distinct из результирующей выборки используя методы, такие как select, pluck и ids; метод order вызовет исключение ActiveRecord::StatementInvalid, если поля, используемые в выражении order, не включены в список выбора. Смотрите следующий раздел по выбору полей из результирующей выборки.
5. Выбор определенных полей
По умолчанию Model.find выбирает все множество полей результата, используя select *.
Чтобы выбрать подмножество полей из всего множества, можете определить его, используя методselect.
Например, чтобы выбрать только столбцы isbn и out_of_print:
Book.select(:isbn, :out_of_print)
# ИЛИ
Book.select("isbn, out_of_print")
Используемый для этого запрос SQL будет иметь подобный вид:
SELECT isbn, out_of_print FROM books
Будьте осторожны, поскольку это также означает, что будет инициализирован объект модели только с теми полями, которые вы выбрали. Если вы попытаетесь обратиться к полям, которых нет в инициализированной записи, то получите:
ActiveModel::MissingAttributeError: missing attribute '<attribute>' for Book
Где <attribute> это атрибут, который был запрошен. Метод id не вызывает ActiveRecord::MissingAttributeError, поэтому будьте аккуратны при работе со связями, так как они нуждаются в методе id для правильной работы.
Если хотите вытащить только по одной записи для каждого уникального значения в определенном поле, можно использовать distinct:
Customer.select(:last_name).distinct
Это сгенерирует такой SQL:
SELECT DISTINCT last_name FROM customers
Также можно убрать ограничение уникальности:
# Возвратит уникальные last_name
query = Customer.select(:last_name).distinct
# Возвратит все last_name, даже если есть дубликаты
query.distinct(false)
6. Ограничение и смещение
Чтобы применить LIMIT к SQL, запущенному с помощью Model.find, нужно определить LIMIT, используя методы limit и offset на relation.
Используйте limit для определения количества записей, которые будут получены, и offset - для числа записей, которые будут пропущены до начала возврата записей. Например:
Customer.limit(5)
возвратит максимум 5 покупателей, и, поскольку не определено смещение, будут возвращены первые 5 в таблице. Выполняемый SQL будет выглядеть подобным образом:
SELECT * FROM customers LIMIT 5
Добавление offset к этому
Customer.limit(5).offset(30)
Возвратит максимум 5 покупателей, начиная с 31-го. SQL выглядит так:
SELECT * FROM customers LIMIT 5 OFFSET 30
7. Группировка
Чтобы применить условие GROUP BY к SQL, можно использовать метод group.
Например, если хотите найти коллекцию дат, в которые были созданы заказы:
Order.select("created_at").group("created_at")
Это выдаст вам отдельный объект Order на каждую дату, для которой были заказы в базе данных.
SQL, который будет выполнен, будет выглядеть так:
SELECT created_at
FROM orders
GROUP BY created_at
7.1. Общее количество сгруппированных элементов
Чтобы получить общее количество сгруппированных элементов одним запросом, вызовите count после group.
irb> Order.group(:status).count
=> {"being_packed"=>7, "shipped"=>12}
SQL, который будет выполнен, будет выглядеть так:
SELECT COUNT (*) AS count_all, status AS status
FROM orders
GROUP BY status
8. Условия HAVING
SQL использует условие HAVING для определения условий для полей, указанных в GROUP BY. Условие HAVING, определенное в SQL, запускается в Model.find с использованием метода having для поиска.
Например:
Order.select("created_at, sum(total) as total_price").
group("created_at").having("sum(total) > ?", 200)
SQL, который будет выполнен, выглядит так:
SELECT created_at as ordered_date, sum(total) as total_price
FROM orders
GROUP BY created_at
HAVING sum(total) > 200
Это возвращает дату и итоговую цену для каждого объекта заказа, сгруппированные по дню, когда они были заказаны, и где цена больше $200.
Получить total_price каждого возвращенного объекта заказа можно так:
big_orders = Order.select("created_at, sum(total) as total_price")
.group("created_at")
.having("sum(total) > ?", 200)
big_orders[0].total_price
# Возвращает итоговую цену первого объекта Order
9. Переопределяющие условия
9.1. unscope
Можете указать определенные условия, которые будут убраны, используя метод unscope. Например:
Book.where('id > 100').limit(20).order('id desc').unscope(:order)
SQL, который будет выполнен, будет выглядеть так:
SELECT * FROM books WHERE id > 100 LIMIT 20
-- Оригинальный запрос без `unscope`
SELECT * FROM books WHERE id > 100 ORDER BY id desc LIMIT 20
Также можно убрать определенные условия where. Например, это уберет условие для id из условия where:
Book.where(id: 10, out_of_print: false).unscope(where: :id)
# SELECT books.* FROM books WHERE out_of_print = 0
Relation, использующий unscope повлияет на любой relation, в который он слит:
Book.order('id desc').merge(Book.unscope(:order))
# SELECT books.* FROM books
9.2. only
Также можно переопределить условия, используя метод only. Например:
Book.where('id > 10').limit(20).order('id desc').only(:order, :where)
SQL, который будет выполнен, будет выглядеть так:
SELECT * FROM books WHERE id > 10 ORDER BY id DESC
-- Оригинальный запрос без `only`
SELECT * FROM books WHERE id > 10 ORDER BY id DESC LIMIT 20
9.3. reselect
Метод reselect переопределяет существующее выражение select. Например:
Book.select(:title, :isbn).reselect(:created_at)
SQL, который будет выполнен:
SELECT books.created_at FROM books
Сравните это со случаем, когда не было использовано выражение reselect:
Book.select(:title, :isbn).select(:created_at)
SQL, который будет выполнен:
SELECT books.title, books.isbn, books.created_at FROM books
9.4. reorder
Метод reorder переопределяет сортировку скоупа по умолчанию. Например, если определение класса включает это:
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
И вы выполняете это:
Author.find(10).books
SQL, который будет выполнен, будет выглядеть так:
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published DESC
Можно использовать выражение reorder для указания иного способа упорядочивания книг:
Author.find(10).books.reorder('year_published ASC')
SQL, который будет выполнен:
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published ASC
9.5. reverse_order
Метод reverse_order меняет направление условия сортировки, если оно определено:
Book.where("author_id > 10").order(:year_published).reverse_order
SQL, который будет выполнен, будет выглядеть так:
SELECT * FROM books WHERE author_id > 10 ORDER BY year_published DESC
Если условие сортировки не было определено в запросе, reverse_order сортирует по первичному ключу в обратном порядке:
Book.where("author_id > 10").reverse_order
SQL, который будет выполнен, будет выглядеть так:
SELECT * FROM books WHERE author_id > 10 ORDER BY books.id DESC
Метод reverse_order не принимает аргументы.
9.6. rewhere
Метод rewhere переопределяет существующее именованное условие where. Например:
Book.where(out_of_print: true).rewhere(out_of_print: false)
SQL, который будет выполнен, будет выглядеть так:
SELECT * FROM books WHERE out_of_print = 0
В случае, когда не используется условие rewhere, условия where соединяются с помощью AND
Book.where(out_of_print: true).where(out_of_print: false)
выполненный SQL будет следующий:
SELECT * FROM books WHERE out_of_print = 1 AND out_of_print = 0
9.7. regroup
Метод regroup переопределяет существующее именованное условие group. Например:
Book.group(:author).regroup(:id)
SQL, который будет выполнен:
SELECT * FROM books GROUP BY id
Если не было бы использовано выражение regroup, выражения группировки объединились:
Book.group(:author).group(:id)
SQL, который был бы выполнен:
SELECT * FROM books GROUP BY author, id
10. Нулевой Relation
Метод none возвращает сцепляемый relation без записей. Любые последующие условия, сцепленные с возвращенным relation, продолжат генерировать пустые relation. Это полезно в случаях, когда необходим сцепляемый отклик на метод или скоуп, который может вернуть пустые результаты.
Book.none # возвращает пустой Relation и не вызывает запросов.
# От метода highlighted_reviews ожидается, что он вернет Relation.
Book.first.highlighted_reviews.average(:rating)
# => Возвращает средний рейтинг книги
class Book
# Возвращает рецензии, когда их как минимум 5,
# иначе рассматривает эту книгу как не рецензированную
def highlighted_reviews
if reviews.count > 5
reviews
else
Review.none # Пока не удовлетворяет минимальному порогу
end
end
end
11. Объекты только для чтения
Active Record предоставляет relation метод readonly для явного запрета на модификацию любого из возвращаемых объектов. Любая попытка изменить запись, доступную только для чтения, не удастся, вызвав исключение ActiveRecord::ReadOnlyRecord.
customer = Customer.readonly.first
customer.visits += 1
customer.save
Так как customer явно указан как объект доступный только для чтения, выполнение вышеуказанного кода выдаст исключение ActiveRecord::ReadOnlyRecord при вызове customer.save с обновленным значением visits.
12. Блокировка записей для обновления
Блокировка полезна для предотвращения состояния гонки при обновлении записей в базе данных и обеспечения атомарного обновления.
Active Record предоставляет два механизма блокировки:
- Оптимистическая блокировка
- Пессимистическая блокировка
12.1. Оптимистическая блокировка
Оптимистическая блокировка позволяет нескольким пользователям обращаться к одной и той же записи для редактирования и предполагает минимум конфликтов с данными. Она осуществляет это с помощью проверки, внес ли другой процесс изменения в записи, с тех пор как она была открыта. Если это происходит, вызывается исключение ActiveRecord::StaleObjectError, и обновление игнорируется.
Столбец оптимистической блокировки
Чтобы начать использовать оптимистическую блокировку, таблица должна иметь столбец, называющийся lock_version, с типом integer. Каждый раз, когда запись обновляется, Active Record увеличивает значение lock_version, и средства блокирования обеспечивают, что для записи, вызванной дважды, та, которая первая успеет, будет сохранена, а для второй будет вызвано исключение ActiveRecord::StaleObjectError.
Например:
c1 = Customer.find(1)
c2 = Customer.find(1)
c1.first_name = "Sandra"
c1.save
c2.first_name = "Michael"
c2.save # вызывает исключение ActiveRecord::StaleObjectError
Вы ответственны за разрешение конфликта с помощью обработки исключения и либо отката, либо объединения, либо применения бизнес-логики, необходимой для разрешения конфликта.
Это поведение может быть отключено, если установить ActiveRecord::Base.lock_optimistically = false.
Для переопределения имени столбца lock_version, ActiveRecord::Base предоставляет атрибут класса locking_column:
class Customer < ApplicationRecord
self.locking_column = :lock_customer_column
end
12.2. Пессимистическая блокировка
Пессимистическая блокировка использует механизм блокировки, предоставленный лежащей в основе базой данных. Использование lock при построении relation применяет эксклюзивную блокировку для выбранных строк. Relations, которые используют lock, обычно упакованы внутри transaction для предотвращения условий взаимной блокировки (дедлока).
Например:
Book.transaction do
book = Book.lock.first
book.title = 'Algorithms, second edition'
book.save!
end
Вышеописанная сессия осуществляет следующие SQL для бэкенда MySQL:
SQL (0.2ms) BEGIN
Book Load (0.3ms) SELECT * FROM books LIMIT 1 FOR UPDATE
Book Update (0.4ms) UPDATE books SET updated_at = '2009-02-07 18:05:56', title = 'Algorithms, second edition' WHERE id = 1
SQL (0.8ms) COMMIT
Также можно передать чистый SQL в опцию lock для разрешения различных типов блокировок. Например, в MySQL есть выражение, называющееся LOCK IN SHARE MODE, которым можно заблокировать запись, но все же разрешить другим запросам читать ее. Чтобы указать это выражения, просто передайте его как опцию блокировки:
Book.transaction do
book = Book.lock("LOCK IN SHARE MODE").find(1)
book.increment!(:views)
end
Отметьте, что ваша база данных должна поддерживать SQL, который вы передаете в метод lock.
Если у вас уже имеется экземпляр модели, можно одновременно начать транзакцию и затребовать блокировку, используя следующий код:
book = Book.first
book.with_lock do
# Этот блок вызывается в транзакции,
# книга уже заблокирован.
book.increment!(:views)
end
13. Соединительные таблицы
Active Record предоставляет два метода поиска для определения условия JOIN в результирующем SQL: joins и left_outer_joins. В то время, как joins следует использовать для INNER JOIN или пользовательских запросов, left_outer_joins используется для запросов с помощью LEFT OUTER JOIN.
13.1. joins
Существует несколько способов использования метода joins.
13.1.1. Использование строкового фрагмента SQL
Можно просто передать чистый SQL, определяющий условие JOIN в joins.
Author.joins("INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE")
Это приведет к следующему SQL:
SELECT authors.* FROM authors INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE
13.1.2. Использование массива/хэша именованных связей
Active Record позволяет использовать имена связей, определенных в модели, как ярлыки для определения условия JOIN этих связей при использовании метода joins.
Все нижеследующее создаст ожидаемые соединительные запросы с использованием INNER JOIN:
13.1.2.1. Соединение одиночной связи
Book.joins(:reviews)
Это создаст:
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
Или, по-русски, "возвратить объект Book для всех книг с рецензиями". Обратите внимание, что будут дублирующиеся книги, если у книги больше одной рецензии. Если нужны уникальные книги, можно использовать Book.joins(:reviews).distinct.
13.1.3. Соединение нескольких связей
Book.joins(:author, :reviews)
Это создаст:
SELECT books.* FROM books
INNER JOIN authors ON authors.id = books.author_id
INNER JOIN reviews ON reviews.book_id = books.id
Или, по-русски, "возвратить все книги, у которых есть автор и как минимум одна рецензия". Снова отметьте, что книги с несколькими рецензиями будут показаны несколько раз.
13.1.3.1. Соединение вложенных связей (одного уровня)
Book.joins(reviews: :customer)
Это создаст:
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
Или, по-русски, "возвратить все книги, у которых есть рецензия покупателя".
13.1.3.2. Соединение вложенных связей (разных уровней)
Author.joins(books: [{ reviews: { customer: :orders } }, :supplier])
Это создаст:
SELECT authors.* FROM authors
INNER JOIN books ON books.author_id = authors.id
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
INNER JOIN orders ON orders.customer_id = customers.id
INNER JOIN suppliers ON suppliers.id = books.supplier_id
Или, по-русски: "возвратить всех авторов, у которых есть книги с рецензиями покупателей, делавших заказы, а также поставщики для этих книг".
13.1.4. Определение условий в соединительных таблицах
В соединительных таблицах можно определить условия, используя обычные массивные и строковые условия. Условия с использованием хэша предоставляют специальный синтаксис для определения условий в соединительных таблицах:
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where('orders.created_at' => time_range).distinct
Это найдет всех покупателей, сделавших вчера заказы, используя выражение SQL BETWEEN для сравнения created_at.
Альтернативный и более чистый синтаксис для этого - вложенные хэш-условия:
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where(orders: { created_at: time_range }).distinct
Для более сложных условий или повторного использования существующих именованных скоупов можно использовать merge. Сперва давайте добавим новый именованный скоуп в модель Order:
class Order < ApplicationRecord
belongs_to :customer
scope :created_in_time_range, ->(time_range) {
where(created_at: time_range)
}
end
Теперь можно использовать merge для слияния со скоупом created_in_time_range:
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).merge(Order.created_in_time_range(time_range)).distinct
Это найдет всех покупателей, сделавших вчера заказы, снова используя выражение SQL BETWEEN.
13.2. left_outer_joins
Если хотите выбрать ряд записей, независимо от того, имеют ли они связанные записи, можно использовать метод left_outer_joins.
Customer.left_outer_joins(:reviews).distinct.select('customers.*, COUNT(reviews.*) AS reviews_count').group('customers.id')
Который создаст:
SELECT DISTINCT customers.*, COUNT(reviews.*) AS reviews_count FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id GROUP BY customers.id
Что означает: "возвратить всех покупателей и количество их рецензий, независимо от того, имеются ли у них вообще рецензии".
13.3. where.associated и where.missing
Методы запроса associated и missing позволяет выбрать набор записей, основываясь на существовании или отсутствии связи.
Используя where.associated:
Customer.where.associated(:reviews)
Создаст:
SELECT customers.* FROM customers
INNER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NOT NULL
Что означает "вернуть всех покупателей, сделавших хотя бы один обзор".
Используя where.missing:
Customer.where.missing(:reviews)
Создаст:
SELECT customers.* FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NULL
Что означает "вернуть всех покупателей, не сделавших ни один обзор".
14. Нетерпеливая загрузка связей
Нетерпеливая загрузка - это механизм загрузки связанных записей объекта, возвращаемых Model.find, с использованием как можно меньшего количества запросов.
14.1. Проблема N + 1 запроса
Рассмотрим следующий код, который находит 10 книг и выводит фамилии их авторов:
books = Book.limit(10)
books.each do |book|
puts book.author.last_name
end
На первый взгляд выглядит хорошо. Но проблема лежит в общем количестве выполненных запросов. Вышеупомянутый код выполняет 1 (чтобы найти 10 книг) + 10 (каждый на одну книгу для загрузки автора) = итого 11 запросов.
14.1.1. Решение проблемы N + 1 запроса
Active Record позволяет заранее указать все связи, которые должны быть загружены.
Методы следующие:
14.2. includes
С помощью includes Active Record убеждается, что все указанные связи загружаются с помощью минимально возможного количества запросов.
Пересмотрев вышеупомянутую задачу, можно переписать Book.limit(10), чтобы нетерпеливо загрузить авторов с помощью метода includes:
books = Book.includes(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
Этот код выполнит всего 2 запроса, вместо 11 запросов из прошлого примера:
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
14.2.1. Нетерпеливая загрузка нескольких связей
Active Record позволяет нетерпеливо загружать любое количество связей в одном вызове Model.find с использованием массива, хэша или вложенного хэша массивов/хэшей с помощью метода includes.
14.2.1.1. Массив нескольких связей
Customer.includes(:orders, :reviews)
Это загрузит всех покупателей и связанные заказы и рецензии для каждого.
14.2.1.2. Вложенный хэш связей
Customer.includes(orders: { books: [:supplier, :author] }).find(1)
Вышеприведенный код находит покупателя с id 1 и нетерпеливо загружает все связанные заказы для него, книги для всех заказов, и автора и поставщика каждой книги.
14.2.2. Определение условий для нетерпеливой загрузки связей
Хотя Active Record и позволяет определить условия для нетерпеливой загрузки связей точно так же, как и в joins, рекомендуем использовать вместо этого joins.
Однако, если сделать так, то можно использовать where как обычно.
Author.includes(:books).where(books: { out_of_print: true })
Это сгенерирует запрос с ограничением LEFT OUTER JOIN, в то время как метод joins сгенерировал бы его с использованием функции INNER JOIN.
SELECT authors.id AS t0_r0, ... books.updated_at AS t1_r5 FROM authors LEFT OUTER JOIN books ON books.author_id = authors.id WHERE (books.out_of_print = 1)
Если бы не было условия where, то сгенерировался бы обычный набор из двух запросов.
Использование where подобным образом будет работать только, если передавать в него хэш. Для фрагментов SQL необходимо использовать references для принуждения соединения таблиц:
Author.includes(:books).where("books.out_of_print = true").references(:books)
Если, в случае с этим запросом includes, не будет ни одной книги ни для одного автора, все авторы все равно будут загружены. При использовании joins (INNER JOIN), соединительные условия должны соответствовать, иначе ни одной записи не будет возвращено.
Если связь нетерпеливо загружена как часть join, любые поля из произвольного выражения select не будут присутствовать в загруженных моделях. Это так, потому что это избыточность, которая должна появиться или в родительской модели, или в дочерней.
14.3. preload
С помощью preload Active Record загружает каждую указанную связь с помощью одного запроса на каждую связь.
Пересмотрим проблему N + 1 запроса, можно переписать Book.limit(10), предварительно загружая авторов:
books = Book.preload(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
Вышеуказанный код выполнит всего лишь 2 запроса, против 11 запросов в прошлом случае:
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.book_id IN (1,2,3,4,5,6,7,8,9,10)
Метод preload использует массив, хэш, или вложенный хэш массивов/хэшей тем же самым образом, как метод includes, чтобы загрузить любое количество связей, с помощь единого вызова Model.find. Однако, в отличие от метода includes, невозможно указать условия для предварительной загрузки связей.
14.4. eager_load
С помощью eager_load Active Record загружает все указанные связи с помощью LEFT OUTER JOIN.
Пересмотрим случай, когда произошел N + 1, с помощью метода eager_load можно переписать связь Book.limit(10) с авторами:
books = Book.eager_load(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
Вышеуказанный код выполнит всего лишь 2 запросов, против 11 запросов в прошлом случае:
SELECT DISTINCT books.id FROM books LEFT OUTER JOIN authors ON authors.book_id = books.id LIMIT 10
SELECT books.id AS t0_r0, books.last_name AS t0_r1, ...
FROM books LEFT OUTER JOIN authors ON authors.book_id = books.id
WHERE books.id IN (1,2,3,4,5,6,7,8,9,10)
Метод eager_load использует массив, хэш, или вложенный хэш массивов/хэшей тем же самым образом, как метод includes, чтобы загрузить любое количество связей, с помощь единого вызова Model.find. Однако, в отличие от метода includes, невозможно указать условия для нетерпеливой загрузки связей.
14.5. strict_loading
Нетерпеливая загрузка может предотвратить N + 1 запрос, но вы все еще можете лениво загружать некоторые связи. Чтобы убедиться, что нет лениво загружаемых связей, можно включить strict_loading.
Включив режим строгой загрузки на relation, будет вызвана ActiveRecord::StrictLoadingViolationError, если запись пытается лениво загрузить связь:
user = User.strict_loading.first
user.comments.to_a # вызовет ActiveRecord::StrictLoadingViolationError
15. Скоупы
Скоупы позволяют задавать часто используемые запросы, к которым можно обращаться как к вызовам метода в связанных объектах или моделях. С помощью этих скоупов можно использовать каждый ранее раскрытый метод, такой как where, joins и includes. Все методы скоупов возвращают объект ActiveRecord::Relation или nil, что позволяет вызывать на них дополнительные методы (такие как другие скоупы).
Для определения простого скоупа мы используем метод scope внутри класса, передав запрос, который хотим запустить при вызове этого скоупа:
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
end
Для вызова скоупа out_of_print, можно вызвать его либо на классе:
irb> Book.out_of_print
=> #<ActiveRecord::Relation> # все распроданные книги
Либо на связи, состоящей из объектов Book:
irb> author = Author.first
irb> author.books.out_of_print
=> #<ActiveRecord::Relation> # все распроданные книги этого `author`
Скоупы также сцепляются с другими скоупами:
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
scope :out_of_print_and_expensive, -> { out_of_print.where("price > 500") }
end
15.1. Передача аргумента
Скоуп может принимать аргументы:
class Book < ApplicationRecord
scope :costs_more_than, ->(amount) { where("price > ?", amount) }
end
Вызывайте скоуп, как будто это метод класса:
irb> Book.costs_more_than(100.10)
Однако, это всего лишь дублирование функциональности, которая должна быть предоставлена методом класса.
class Book < ApplicationRecord
def self.costs_more_than(amount)
where("price > ?", amount)
end
end
Эти методы также будут доступны на связанных объектах:
irb> author.books.costs_more_than(100.10)
15.2. Использование условий
Ваши скоупы могут использовать условия:
class Order < ApplicationRecord
scope :created_before, ->(time) { where(created_at: ...time) if time.present? }
end
Подобно остальным примерам, это ведет себя подобно методу класса.
class Order < ApplicationRecord
def self.created_before(time)
where(created_at: ...time) if time.present?
end
end
Однако, имеется одно важное предостережение: скоуп всегда должен возвращать объект ActiveRecord::Relation, даже если условие вычисляется false, в отличие от метода класса, возвращающего nil. Это может вызвать NoMethodError при сцеплении методов класса с условиями, если одно из условий вернет false.
15.3. Применение скоупа по умолчанию
Если хотите, чтобы скоуп был применен ко всем запросам модели, можно использовать метод default_scope в самой модели.
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
Когда запросы для этой модели будут выполняться, запрос SQL теперь будет выглядеть примерно так:
SELECT * FROM books WHERE (out_of_print = false)
Если необходимо сделать более сложные вещи со скоупом по умолчанию, альтернативно его можно определить как метод класса:
class Book < ApplicationRecord
def self.default_scope
# Должен возвращать ActiveRecord::Relation.
end
end
default_scope также применяется при создании записи, когда аргументы скоупа передаются как Hash. Он не применяется при обновлении записи. То есть:
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: false>
irb> Book.unscoped.new
=> #<Book id: nil, out_of_print: nil>
Имейте в виду, что когда передаются в формате Array, аргументы запроса default_scope не могут быть преобразованы в Hash для назначения атрибутов по умолчанию. То есть:
class Book < ApplicationRecord
default_scope { where("out_of_print = ?", false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: nil>
15.4. Объединение скоупов
Подобно условиям where, скоупы объединяются с использованием AND.
class Book < ApplicationRecord
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :recent, -> { where(year_published: 50.years.ago.year..) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
end
irb> Book.out_of_print.old
SELECT books.* FROM books WHERE books.out_of_print = 'true' AND books.year_published < 1969
Можно комбинировать условия scope и where, и результирующий SQL будет содержать все условия, соединенные с помощью AND.
irb> Book.in_print.where(price: ...100)
SELECT books.* FROM books WHERE books.out_of_print = 'false' AND books.price < 100
Если необходимо, чтобы сработало только последнее условие where, тогда можно использовать merge.
irb> Book.in_print.merge(Book.out_of_print)
SELECT books.* FROM books WHERE books.out_of_print = true
Важным предостережением является то, что default_scope переопределяется условиями scope и where.
class Book < ApplicationRecord
default_scope { where(year_published: 50.years.ago.year..) }
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
end
irb> Book.all
SELECT books.* FROM books WHERE (year_published >= 1969)
irb> Book.in_print
SELECT books.* FROM books WHERE (year_published >= 1969) AND books.out_of_print = false
irb> Book.where('price > 50')
SELECT books.* FROM books WHERE (year_published >= 1969) AND (price > 50)
Как видите, default_scope объединяется как со scope, так и с where условиями.
15.5. Удаление всех скоупов
Если хотите удалить скоупы по какой-то причине, можете использовать метод unscoped. Это особенно полезно, если в модели определен default_scope, и он не должен быть применен для конкретно этого запроса.
Book.unscoped.load
Этот метод удаляет все скоупы и выполняет обычный запрос к таблице.
irb> Book.unscoped.all
SELECT books.* FROM books
irb> Book.where(out_of_print: true).unscoped.all
SELECT books.* FROM books
unscoped также может принимать блок:
irb> Book.unscoped { Book.out_of_print }
SELECT books.* FROM books WHERE books.out_of_print
16. Динамический поиск
Для каждого поля (также называемого атрибутом), определенного в вашей таблице, Active Record предоставляет метод поиска. Например, если есть поле first_name в вашей модели Customer, вы автоматически получаете find_by_first_name от Active Record. Если также есть поле locked в модели Customer, вы также получаете find_by_locked метод.
Можете определить восклицательный знак (!) в конце динамического поиска, чтобы он вызвал ошибку ActiveRecord::RecordNotFound, если не возвратит ни одной записи, например так Customer.find_by_first_name!("Ryan")
Если хотите искать и по first_name, и по orders_count, можете сцепить эти поиски вместе, просто написав "and" между полями, например, Customer.find_by_first_name_and_orders_count("Ryan", 5).
17. Перечисление
Перечисление позволяет определить массив значений для атрибута, и ссылаться на них по имени. Фактическим значением, хранимым в базе данных, будет целое число, соответствующее одному из значений.
Объявление перечисления:
- Создаст скоупы, которые можно использовать для поиска всех объектов имеющих или не имеющих одно из значений перечисления
- Создаст метод экземпляра, который можно использовать для определения, имеет ли объект определенное значение для перечисления
- Создаст метод экземпляра, который можно использовать для изменения значения перечисления у объекта
для каждого возможного значения перечисления.
Например, дано это определение enum:
class Order < ApplicationRecord
enum :status, [:shipped, :being_packaged, :complete, :cancelled]
end
Эти скоупы будут автоматически созданы, и их можно использовать, чтобы найти все объекты с или без определенного значения для status.
irb> Order.shipped
=> #<ActiveRecord::Relation> # все заказы со status == :shipped
irb> Order.not_shipped
=> #<ActiveRecord::Relation> # все заказы со status != :shipped
Эти методы экземпляра создаются автоматически и запрашивают, имеет ли модель это значение для перечисления status:
irb> order = Order.shipped.first
irb> order.shipped?
=> true
irb> order.complete?
=> false
Эти методы экземпляра создаются автоматически, и сначала обновляют значение status на названное значение, а затем запрашивают, был ли успешно установлен статус:
irb> order = Order.first
irb> order.shipped!
UPDATE "orders" SET "status" = ?, "updated_at" = ? WHERE "orders"."id" = ? [["status", 0], ["updated_at", "2019-01-24 07:13:08.524320"], ["id", 1]]
=> true
Полную документацию об enum можно найти в документации Rails API.
18. Понимание цепочек методов
В Active Record есть полезный приём программирования Method Chaining, который позволяет нам комбинировать множество Active Record методов.
Можно сцепить несколько методов в единое выражение, если предыдущий вызываемый метод возвращает ActiveRecord::Relation, такие как all, where и joins. Методы, которые возвращают одиночный объект (смотрите раздел Получение одиночного объекта) должны вызываться в конце.
Ниже представлены несколько примеров. Это руководство не покрывает все возможности, а только некоторые, для ознакомления. Когда вызывается Active Record метод, запрос не сразу генерируется и отправляется в базу. Запрос посылается только тогда, когда данные реально необходимы. Таким образом, каждый пример ниже генерирует только один запрос.
18.1. Получение отфильтрованных данных из нескольких таблиц
Customer
.select('customers.id, customers.last_name, reviews.body')
.joins(:reviews)
.where('reviews.created_at > ?', 1.week.ago)
Результат должен быть примерно следующим:
SELECT customers.id, customers.last_name, reviews.body
FROM customers
INNER JOIN reviews
ON reviews.customer_id = customers.id
WHERE (reviews.created_at > '2019-01-08')
18.2. Получение определённых данных из нескольких таблиц
Book
.select('books.id, books.title, authors.first_name')
.joins(:author)
.find_by(title: 'Abstraction and Specification in Program Development')
Выражение выше, сгенерирует следующий SQL-запрос:
SELECT books.id, books.title, authors.first_name
FROM books
INNER JOIN authors
ON authors.id = books.author_id
WHERE books.title = $1 [["title", "Abstraction and Specification in Program Development"]]
LIMIT 1
Обратите внимание, что если запросу соответствует несколько записей, find_by вернет только первую запись и проигнорирует остальные (смотрите LIMIT 1 выше).
19. Поиск или создание нового объекта
Часто бывает, что вам нужно найти запись или создать ее, если она не существует. Вы можете сделать это с помощью методов find_or_create_by и find_or_create_by!.
19.1. find_or_create_by
Метод find_or_create_by проверяет, существует ли запись с определенными атрибутами. Если нет, то вызывается create. Давайте рассмотрим пример.
Предположим, вы хотите найти покупателя по имени "Andy", и, если такого нет, создать его. Это можно сделать, выполнив:
irb> Customer.find_or_create_by(first_name: 'Andy')
=> #<Customer id: 5, first_name: "Andy", last_name: nil, title: nil, visits: 0, orders_count: nil, lock_version: 0, created_at: "2019-01-17 07:06:45", updated_at: "2019-01-17 07:06:45">
SQL, генерируемый этим методом, будет выглядеть так:
SELECT * FROM customers WHERE (customers.first_name = 'Andy') LIMIT 1
BEGIN
INSERT INTO customers (created_at, first_name, locked, orders_count, updated_at) VALUES ('2011-08-30 05:22:57', 'Andy', 1, NULL, '2011-08-30 05:22:57')
COMMIT
find_or_create_by возвращает либо уже существующую запись, либо новую запись. В нашем случае, у нас еще нет покупателя с именем Andy, поэтому запись будет создана и возвращена.
Новая запись может быть не сохранена в базу данных; это зависит от того, прошли валидации или нет (подобно create).
Предположим, мы хотим установить атрибут 'locked' как false, если создаем новую запись, но не хотим включать его в запрос. Таким образом, мы хотим найти покупателя по имени "Andy" или, если этот покупатель не существует, создать покупателя по имени "Andy", который не заблокирован.
Этого можно достичь двумя способами. Первый - это использование create_with:
Customer.create_with(locked: false).find_or_create_by(first_name: 'Andy')
Второй способ - это использование блока:
Customer.find_or_create_by(first_name: 'Andy') do |c|
c.locked = false
end
Блок будет выполнен, только если покупателя был создан. Во второй раз, при запуске этого кода, блок будет проигнорирован.
19.2. find_or_create_by!
Можно также использовать find_or_create_by!, чтобы вызвать исключение, если новая запись невалидна. Валидации не раскрываются в этом руководстве, но давайте на момент предположим, что вы временно добавили
validates :orders_count, presence: true
в модель Customer. Если попытаетесь создать нового Customer без передачи orders_count, запись будет невалидной и будет вызвано исключение:
irb> Customer.find_or_create_by!(first_name: 'Andy')
ActiveRecord::RecordInvalid: Validation failed: Orders count can’t be blank
19.3. find_or_initialize_by
Метод find_or_initialize_by работает похоже на find_or_create_by, но он вызывает не create, а new. Это означает, что новый экземпляр модели будет создан в памяти, но не будет сохранен в базу данных. Продолжая пример с find_or_create_by, теперь нам нужен покупатель по имени 'Nina':
irb> nina = Customer.find_or_initialize_by(first_name: 'Nina')
=> #<Customer id: nil, first_name: "Nina", orders_count: 0, locked: true, created_at: "2011-08-30 06:09:27", updated_at: "2011-08-30 06:09:27">
irb> nina.persisted?
=> false
irb> nina.new_record?
=> true
Поскольку объект еще не сохранен в базу данных, сгенерированный SQL выглядит так:
SELECT * FROM customers WHERE (customers.first_name = 'Nina') LIMIT 1
Когда захотите сохранить его в базу данных, просто вызовите save:
irb> nina.save
=> true
20. Поиск с помощью SQL
Если вы предпочитаете использовать собственные запросы SQL для поиска записей в таблице, можете использовать find_by_sql. Метод find_by_sql возвратит массив объектов, даже если лежащий в основе запрос вернет всего лишь одну запись. Например, можете запустить такой запрос:
irb> Customer.find_by_sql("SELECT * FROM customers INNER JOIN orders ON customers.id = orders.customer_id ORDER BY customers.created_at desc")
=> [#<Customer id: 1, first_name: "Lucas" ...>, #<Customer id: 2, first_name: "Jan" ...>, ...]
find_by_sql предоставляет простой способ создания произвольных запросов к базе данных и получения экземпляров объектов.
20.1. select_all
У find_by_sql есть близкий родственник, называемый connection.select_all. select_all получит объекты из базы данных, используя произвольный SQL, как и в find_by_sql, но не создаст их экземпляры. Этот метод вернет экземпляр класса ActiveRecord::Result и вызов to_a на этом объекте вернет массив хэшей, где каждый хэш указывает на запись.
irb> Customer.connection.select_all("SELECT first_name, created_at FROM customers WHERE id = '1'").to_a
=> [{"first_name"=>"Rafael", "created_at"=>"2012-11-10 23:23:45.281189"}, {"first_name"=>"Eileen", "created_at"=>"2013-12-09 11:22:35.221282"}]
20.2. pluck
pluck может быть использован для подбора значения(-ий) из названного столбца(-ов) в текущем relation. Он принимает список имен столбцов как аргумент и возвращает массив значений определенных столбцов соответствующего типа данных.
irb> Book.where(out_of_print: true).pluck(:id)
SELECT id FROM books WHERE out_of_print = true
=> [1, 2, 3]
irb> Order.distinct.pluck(:status)
SELECT DISTINCT status FROM orders
=> ["shipped", "being_packed", "cancelled"]
irb> Customer.pluck(:id, :first_name)
SELECT customers.id, customers.first_name FROM customers
=> [[1, "David"], [2, "Fran"], [3, "Jose"]]
pluck позволяет заменить такой код:
Customer.select(:id).map { |c| c.id }
# или
Customer.select(:id).map(&:id)
# или
Customer.select(:id, :first_name).map { |c| [c.id, c.first_name] }
на:
Customer.pluck(:id)
# или
Customer.pluck(:id, :first_name)
В отличие от select, pluck непосредственно конвертирует результат запроса в массив Ruby, без создания объектов ActiveRecord. Это может означать лучшую производительность для больших или часто используемых запросов. Однако, любые переопределения методов в модели будут недоступны. Например:
class Customer < ApplicationRecord
def name
"I am #{first_name}"
end
end
irb> Customer.select(:first_name).map &:name
=> ["I am David", "I am Jeremy", "I am Jose"]
irb> Customer.pluck(:first_name)
=> ["David", "Jeremy", "Jose"]
Вы не ограничены запросом полей из одиночной таблицы, также можно запрашивать несколько таблиц.
irb> Order.joins(:customer, :books).pluck("orders.created_at, customers.email, books.title")
Более того, в отличие от select и других скоупов Relation, pluck вызывает немедленный запрос, и поэтому не может быть соединен с любыми последующими скоупами, хотя он может работать со скоупами, подключенными ранее:
irb> Customer.pluck(:first_name).limit(1)
NoMethodError: undefined method `limit' for #<Array:0x007ff34d3ad6d8>
irb> Customer.limit(1).pluck(:first_name)
=> ["David"]
Следует знать, что использование pluck запустит нетерпеливую загрузку, если объект relation содержит включаемые значения, даже если нетерпеливая загрузка не нужна для запроса. Например:
irb> assoc = Customer.includes(:reviews)
irb> assoc.pluck(:id)
SELECT "customers"."id" FROM "customers" LEFT OUTER JOIN "reviews" ON "reviews"."id" = "customers"."review_id"
Один из способов избежать этого — unscope на includes:
irb> assoc.unscope(:includes).pluck(:id)
20.3. pick
pick может быть использован для подбора значения(-ий) из названного столбца(-ов) в текущем relation. Он принимает список имен столбцов как аргумент и возвращает первый ряд значений указанного столбца с соответствующим типом данных. pick это сокращение для relation.limit(1).pluck(*column_names).first, которой, в основном, полезно, когда у вас уже имеется relation, ограниченное одним рядом.
pick позволяет заменить код, такой как:
Customer.where(id: 1).pluck(:id).first
на:
Customer.where(id: 1).pick(:id)
20.4. ids
ids может быть использован для сбора всех ID для relation, используя первичный ключ таблицы.
irb> Customer.ids
SELECT id FROM customers
class Customer < ApplicationRecord
self.primary_key = "customer_id"
end
irb> Customer.ids
SELECT customer_id FROM customers
21. Существование объектов
Если вы просто хотите проверить существование объекта, есть метод, называемый exists?. Этот метод запрашивает базу данных, используя тот же запрос, что и find, но вместо возврата объекта или коллекции объектов, он возвращает или true, или false.
Customer.exists?(1)
Метод exists? также принимает несколько значений, при этом возвращает true, если хотя бы одна из этих записей существует.
Customer.exists?(id: [1, 2, 3])
# или
Customer.exists?(first_name: ['Jane', 'Sergei'])
Даже возможно использовать exists? без аргументов на модели или relation:
Customer.where(first_name: 'Ryan').exists?
Пример выше вернет true, если есть хотя бы один покупатель с first_name 'Ryan', и false в противном случае.
Customer.exists?
Это возвратит false, если таблица customers пустая, и true в противном случае.
Для проверки на существование также можно использовать any? и many? на модели или relation. many? будет использовать SQL count, для определения, существует ли элемент.
# на модели
Order.any?
# SELECT 1 FROM orders LIMIT 1
Order.many?
# SELECT COUNT(*) FROM (SELECT 1 FROM orders LIMIT 2)
# на именованном скоупе
Order.shipped.any?
# SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 1
Order.shipped.many?
# SELECT COUNT(*) FROM (SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 2)
# на relation
Book.where(out_of_print: true).any?
Book.where(out_of_print: true).many?
# на связи
Customer.first.orders.any?
Customer.first.orders.many?
22. Вычисления
Этот раздел использует count для примера в этой преамбуле, но описанные опции применяются ко всем подразделам.
Все методы вычисления работают прямо на модели:
irb> Customer.count
SELECT COUNT(*) FROM customers
Или на relation:
irb> Customer.where(first_name: 'Ryan').count
SELECT COUNT(*) FROM customers WHERE (first_name = 'Ryan')
Можно также использовать различные методы поиска на relation для выполнения сложных вычислений:
irb> Customer.includes("orders").where(first_name: 'Ryan', orders: { status: 'shipped' }).count
Что выполнит:
SELECT COUNT(DISTINCT customers.id) FROM customers
LEFT OUTER JOIN orders ON orders.customer_id = customers.id
WHERE (customers.first_name = 'Ryan' AND orders.status = 0)
при условии что в Order есть enum status: [ :shipped, :being_packed, :cancelled ]
22.1. count
Если хотите увидеть, сколько записей есть в таблице модели, можете вызвать Customer.count, и он возвратит число. Если хотите быть более определенным и найти всех покупателей с присутствующим в базе данных титулом, используйте Customer.count(:title).
Про опции смотрите выше в разделе Вычисления.
22.2. average
Если хотите увидеть среднее значение определенного показателя в одной из ваших таблиц, можно вызвать метод average для класса, относящегося к таблице. Вызов этого метода выглядит так:
Order.average("subtotal")
Это возвратит число (возможно, с плавающей запятой, такое как 3.14159265), представляющее среднее значение поля.
Про опции смотрите выше в разделе Вычисления.
22.3. minimum
Если хотите найти минимальное значение поля в таблице, можете вызвать метод minimum для класса, относящегося к таблице. Вызов этого метода выглядит так:
Order.minimum("subtotal")
Про опции смотрите выше в разделе Вычисления.
22.4. maximum
Если хотите найти максимальное значение поля в таблице, можете вызвать метод maximum для класса, относящегося к таблице. Вызов этого метода выглядит так:
Order.maximum("subtotal")
Про опции смотрите выше в разделе Вычисления.
22.5. sum
Если хотите найти сумму полей для всех записей в таблице, можете вызвать метод sum для класса, относящегося к таблице. Вызов этого метода выглядит так:
Order.sum("subtotal")
Про опции смотрите выше в разделе Вычисления.
23. Запуск EXPLAIN
Можно запустить explain на запросах, вызываемых в relations. Вывод EXPLAIN различается для каждой базы данных.
Например, запуск
Customer.where(id: 1).joins(:orders).explain
может выдать
EXPLAIN SELECT `customers`.* FROM `customers` INNER JOIN `orders` ON `orders`.`customer_id` = `customers`.`id` WHERE `customers`.`id` = 1
+----+-------------+------------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+------------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+------------+-------+---------------+
+---------+---------+-------+------+-------------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------------+
| PRIMARY | 4 | const | 1 | |
| NULL | NULL | NULL | 1 | Using where |
+---------+---------+-------+------+-------------+
2 rows in set (0.00 sec)
для MySQL и MariaDB.
Active Record применяет красивое форматирование, эмулирующее работу соответствующей оболочки базы данных. Таким образом, запуск того же запроса с адаптером PostgreSQL выдаст вместо этого
EXPLAIN SELECT "customers".* FROM "customers" INNER JOIN "orders" ON "orders"."customer_id" = "customers"."id" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=4.33..20.85 rows=4 width=164)
-> Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
-> Bitmap Heap Scan on orders (cost=4.18..12.64 rows=4 width=8)
Recheck Cond: (customer_id = '1'::bigint)
-> Bitmap Index Scan on index_orders_on_customer_id (cost=0.00..4.18 rows=4 width=0)
Index Cond: (customer_id = '1'::bigint)
(7 rows)
Нетерпеливая загрузка может вызвать более одного запроса за раз, и некоторым запросам могут потребоваться результаты предыдущих. Поэтому explain фактически выполняет запрос, а затем запрашивает планы запросов. Например,
Customer.where(id: 1).includes(:orders).explain
может выдать это для MySQL и MariaDB:
EXPLAIN SELECT `customers`.* FROM `customers` WHERE `customers`.`id` = 1
+----+-------------+-----------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+-----------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
+----+-------------+-----------+-------+---------------+
+---------+---------+-------+------+-------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------+
| PRIMARY | 4 | const | 1 | |
+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
EXPLAIN SELECT `orders`.* FROM `orders` WHERE `orders`.`customer_id` IN (1)
+----+-------------+--------+------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+--------+------+---------------+
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+--------+------+---------------+
+------+---------+------+------+-------------+
| key | key_len | ref | rows | Extra |
+------+---------+------+------+-------------+
| NULL | NULL | NULL | 1 | Using where |
+------+---------+------+------+-------------+
1 row in set (0.00 sec)
и может выдать это для PostgreSQL:
Customer Load (0.3ms) SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
Order Load (0.3ms) SELECT "orders".* FROM "orders" WHERE "orders"."customer_id" = $1 [["customer_id", 1]]
=> EXPLAIN SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
(2 rows)
23.1. Опции Explain
Для баз данных и адаптеров, поддерживающих их (в настоящее время PostgreSQL и MySQL), можно передать опции, чтобы предоставить углубленный анализ.
Для PostgreSQL, следующее:
Customer.where(id: 1).joins(:orders).explain(:analyze, :verbose)
выдаст:
EXPLAIN (ANALYZE, VERBOSE) SELECT "shop_accounts".* FROM "shop_accounts" INNER JOIN "customers" ON "customers"."id" = "shop_accounts"."customer_id" WHERE "shop_accounts"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.30..16.37 rows=1 width=24) (actual time=0.003..0.004 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Inner Unique: true
-> Index Scan using shop_accounts_pkey on public.shop_accounts (cost=0.15..8.17 rows=1 width=24) (actual time=0.003..0.003 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Index Cond: (shop_accounts.id = '1'::bigint)
-> Index Only Scan using customers_pkey on public.customers (cost=0.15..8.17 rows=1 width=8) (never executed)
Output: customers.id
Index Cond: (customers.id = shop_accounts.customer_id)
Heap Fetches: 0
Planning Time: 0.063 ms
Execution Time: 0.011 ms
(12 rows)
Для MySQL или MariaDB, следующее:
Customer.where(id: 1).joins(:orders).explain(:analyze)
выдаст:
ANALYZE SELECT `shop_accounts`.* FROM `shop_accounts` INNER JOIN `customers` ON `customers`.`id` = `shop_accounts`.`customer_id` WHERE `shop_accounts`.id` = 1
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | r_rows | filtered | r_filtered | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | no matching row in const table |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
1 row in set (0.00 sec)
Опции EXPLAIN и ANALYZE варьируются для разных версий MySQL и MariaDB. (MySQL 5.7, MySQL 8.0, MariaDB)
23.2. Интерпретация EXPLAIN
Интерпретация результатов EXPLAIN находится за рамками этого руководства. Может быть полезной следующая информация:
SQLite3: EXPLAIN QUERY PLAN
MySQL: EXPLAIN Output Format
MariaDB: EXPLAIN
PostgreSQL: Using EXPLAIN

Лицензия CC BY-SA 4.0
"Rails", "Ruby on Rails" и логотип Rails - торговые марки DHH